Codificação de caractere e o Ubuntu pt_BR
Codificação de caractere e o Ubuntu pt_BR
O suporte a idiomas e configurações regionais internacionais — a chamada localização oulocale — nos sistemas operacionais e seus aplicativos envolve uma série de aspectos, como: tradução de mensagens; formatos de data, número e moeda; codificação de caractere.
O Ubuntu Linux é uma excelente distribuição livre baseada na Debian, com bom suporte a dispositivos, aplicativos e idiomas. Porém, esta distribuição pode trazer uma pequena dificuldade no suporte ao Português do Brasil: a codificação de caractere. Verifiquei existência dessa situação nas versões do Ubuntu 6.06 LTS (codinome Dapper Drake) e 7.04 (Feisty Fawn). Pode ocorrer em outras versões, mas não testei.
Eis aqui do que se trata e como resolver eventual dificuldade ou incompatibilidade.
Codificação de caracteres
Codificação de caractere é um aspecto técnico existente nos computadores e dispositivos digitais em geral. Para entendê-lo, é preciso saber que toda informação em um computador é armazenada como “bits e bytes”, ou trocando em miúdos, codificada como códigos numéricos. O byte ou octeto é um conjunto de 8 bits (dígitos binários = 0 ou 1) que pode ser representado como um número inteiro entre 0 (00000000) e 255 (11111111).
Cada caractere textual — letra (maiúscula ou minúscula. acentuada ou não), algarismo e símbolo — com o qual o computador lida deve ser representando como um número para que possa ser armazenado em arquivo, transmitido em rede etc. de forma padronizada. O sistema que define uma tabela padronizada com o conjunto de caracteres possíveis em determinado idioma e seus respectivos formatos de representação numérica é chamado codificação de caractere.
Para a maioria do mundo ocidental que usa o alfabeto latino ou romano, um Byte com seus 256 valores possíveis é suficiente para representar todos os caracteres mais comuns dos idiomas, incluindo as letras acentuadas. Existe um padrão internacional para essa codificação de caractere Ocidental denominado ISO/IEC 8859-1. É este padrão que Brasil, Portugal e outros países ocidentais de língua latina em geral utilizam em seus sistemas de computador, principalmente na plataforma Windows.
Alguns idiomas utilizam símbolos e acentuações menos comuns do alfabeto latino e, para estes, existem variações do padrão ISO 8859, como o ISO-8859-15 entre outros. Já idiomas orientais como o japonês e o chinês podem possuir milhares de símbolos em seus alfabetos de forma que apenas um byte não consegue conter toda sua diversidade. Em função disto, existe um padrão internacional de codificação que contempla alfabetos do mundo todo, chamadoUnicode (veja unicode.org) ou Universal Character Set (UCS).
Existem alguns formatos de codificação de caractere baseados no Unicode/UCS. Um é o UTF-16 (também conhecido como UCS-2), que usa 16 bits (ou 2 bytes/octetos) para representar os caracteres, o que permite 65526 possibilidades e assim comporta grande diversidade de alfabetos. Como UTF-16 é uma codificação bem diferente da ocidental comum que usa apenas 1 byte, a codificação UTF-8 tenta ser um meio-termo: usa 8 bits para representar os 128 caracteres ASCII básicos, 16 bits para caracteres latinos acentuados e alguns outros alfabetos (como Grego), e 3 ou 4 octetos para demais caracteres e alfabetos.
Assim, caracteres latinos acentuados têm código de 8 bits na ISO 8859-1 mas são codificados no UTF-8 com 16 bits. Ou seja, caracteres latinos acentuados são representados diferentemente em ISO 8859-1 e UTF-8. Os bytes resultantes armazenados são diferentes. Saber em que formato um arquivo ou conteúdo textual qualquer está representado/armazenado é essencial para interpretá-lo corretamente.
Problema e solução no Ubuntu
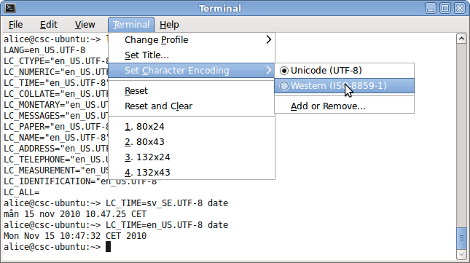
O problema é que, para o idioma Português do Brasil no Ubuntu (6.06 LTS, 7.04), a codificação de caractere definida como padrão foi a UTF-8, quando o padrão mais comum no país é o ISO-8859-1. O resultado prático dessa divergência é que alguns caracteres acentuados — lidos de arquivos gravados em ISO-8859-1, mas indevidamente interpretados como UTF-8 — não são exibidos corretamente, muitas vezes aparecendo como uma interrogação ou outros símbolos estranhos.
Para corrigir o problema, basta definir a codificação de caractere padrão como ISO-8859-1 no locale para Português do Brasil (pt_BR), conforme apresentado neste texto: ISO-8859-1 no Dapper (FINAL). Reproduzo os passos a seguir:
- Certifique-se que os seguintes pacotes estejam instalados:
- language-pack-pt
- language-pack-pt-base
Para instalar, você pode usar o Gerenciador de Pacotes Synaptic (gráfico), ou executar esta linha de comando (requer sudo / permissão de root):
$sudo apt-get install language-pack-pt language-pack-pt-base - Edite o arquivo /var/lib/locales/supported.d/local e adicione a seguinte linha no início do arquivo (requer sudo / permissão de root):
pt_BR.ISO-8859-1 ISO-8859-1 - Edite o arquivo /etc/locale.alias e adicione a seguinte linha (requer sudo / permissão de root):
pt_BR pt_BR.ISO-8859-1 - Edite o arquivo /etc/environment e altere o parâmetro LANG da seguinte forma (requer sudo / permissão de root):
LANG="pt_BR" - Atualize os locales, com o comando (requer sudo / permissão de root):
$sudo dpkg-reconfigure locales - Para ativar imediatamente as novas configurações no ambiente gráfico, reinicie o seu X, com a seguinte combinação de teclas:
[Ctrl] + [Alt] + [Backspace] - Abra o arquivo ~.bashrc (no seu home) e adicione a seguinte linha no final do arquivo [NOTA: para mim, este passo não foi necessário]:
source /etc/environment
Problemas similares
Agora que você já sabe da divergência entre os padrões de codificação de caractere ISO-8859-1 e UTF-8, saiba também que em vários outros ambientes pode ocorrer este problema, quando um conteúdo gravado em ISO-8859-1 é incorretamente classificado ou assumido como UTF-8, ou vice-versa, levando à exibição incorreta.
Um situação comum ocorre na web. Se você abrir uma página web e caracteres estranhos aparecerem no lugar da acentuação, é provável que a identificação de codificação de caractere da página tenha sido incorreta.
Em geral, a causa do problema é um erro de configuração no servidor web ou no sistema operacional deste, onde a codificação de caractere padrão esteja definida como UTF-8, mas a página web apresentada usa efetivamente ISO-8859-1, ou vice-versa. Isso faz com que o servidor web especifique no cabeçalho HTTP o conjunto de caracteres (Content-Type charset, conforme RFC 2616 seção 14.17) incorreto.
Outras vezes, a culpa é da própria página HTML, que pode ter informado o conjunto de caracteres incorreto em suas tags de configuração (meta http-equiv=”Content-Type” ou xml encoding). De uma forma ou de outra, a informação errada fornecida ao navegador web induz ao erro na exibição.
Nestes casos, primeiro tente a seleção automática de codificação, usando a opção de menu Exibir » Codificação » Selecionar automaticamente/Universal (Mozilla Firefox) ou Seleção automática (Internet Explorer). Se não funcionar, você pode contornar o problema de uma página ou site específico forçando manualmente a codificação de caractere, para UTF-8 ou ISO-8859-1, no menu Exibir » Codificação do navegador. Ao sair da página ou site problemático, lembre-se de retornar a codificação de caractere no navegador para automática.
Olhando à frente para internacionalização
Embora o padrão ISO-8859-1 seja atualmente muito adotado em arquivos texto no Brasil — em grande parte por coincidir com a página de código padrão do Windows em Português e outros países ocidentais — e comporte de forma satisfatória os caracteres acentuados do alfabeto latino ocupando um byte por caractere, ele não é uma imposição.
Em conteúdo e aplicações, principalmente na Internet, onde aspectos de internacionalização são importantes, o formato Unicode com a codificação UTF-8 é a principal alternativa quando se deseja ou se necessita uma codificação universal que comporte qualquer idioma.
Se sua prioridade não for compatibilidade com conteúdo legado em codificação ISO-8859-1 e sim suporte a internacionalização, o UTF-8 padrão do Ubuntu é opção adequada.
Para saber mais (maioria em inglês):
- A tutorial on character code issues, em Characters and encodings, por Jukka “Yucca” Korpela.
- Firefox: Por que algumas páginas não mostram palavras acentuadas?, em Firefox Central Brasil.
- Unicode, por Rafael Benevides, 2008-01-04.
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!), por Joel Spolsky, 2003-10-08, em Joel on Software.
- Setting up Windows Internet Explorer 5, 5.5 and 6 for Multilingual and Unicode Support e Unicode Support in HTML, HTML Editors and Web Browsers, por Alan Wood, Unicode Resources.
- UTF-8 and Unicode FAQ for Unix/Linux, por Markus Kuhn.
- Latin 1 and Unicode characters in &ersand; entities, por Jane Austen.
- Survival guide to i18n, por Sam Ruby.
- Mapeamento de Caracteres Estendidos, por Márcio d’Ávila, 2007-06-16.
- De UTF-8 para ISO-8859-1 e vice-versa, por Bruno Rossetto Machado, 2008-03-05.
- Cedilha, Gnome, KDE e Ubuntu 8.04 em Inglês, por Vitor Pamplona, 2009-04-18.
Fonte : http://blog.mhavila.com.br/2006/09/24/codificacao-de-caractere-e-o-ubuntu-pt_br/

Comentários
Postar um comentário